Kafka consumer – understanding fetch memory usage
Kafka is a distributed event store and stream processing system. Multiple producers can write to topics and multiple consumers can consume from the topics. Topics can have multiple partitions and event order is guaranteed at partition level. Let’s see how consumers consume messages from kafka. In this post I will try to describe how to control amount of data Java KafkaConsumer fetches from brokers for each poll call.

How Kafka consumer fetches records
Parallel processing is provided through consumer groups. Consumer groups can have multiple consumers. There are three possible scenarios with respect number of consumers and number of partitions in the topic
When the number of consumers is equal to the number of partitions, each consumer will be assigned one partition from the topic.
If the number of consumers are less than the number of partitions, then few consumers will have more than one partition assigned to them.
If there are more consumers than the number of partitions, then few consumers will not have any assigned partitions. This is not optimal use of resources, we should avoid this case
From above three cases, we can conclude that a consumer can zero or more partitions assigned to it from one or more topics ( a consumer can consume from more than one topic)
For example, consider topic1 has three partitions t1-p0, t1-p1, t1-p2, t1-p3 and t1-p4. consumer-group-1 has two consumers, consumer-1 and consumer-2. Then following is one possible assignments for this setup
Consumer-1 -> t1-p0, t1-p1, t1-p4
Consumer-2 -> t1-p2, t1-p3
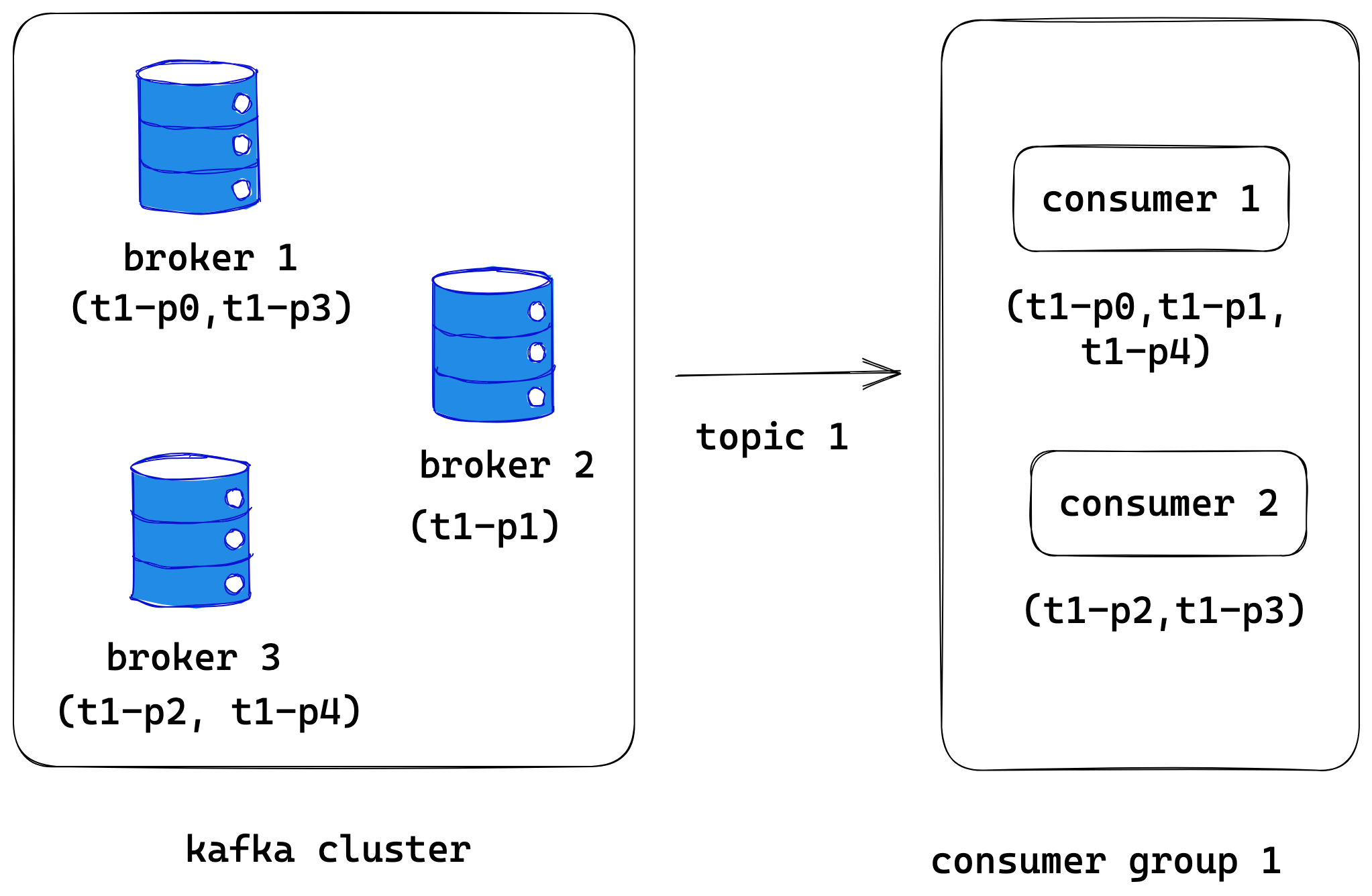
Partition assignment can be controlled by implementing a partitioning strategy or by using already available strategies. In the kafka cluster, each partition will have one leader broker. By default consumers will only read from the partition leader.
Kafka uses a binary protocol on top of TCP. Amount of data returned by the broker for a fetch request can be controlled by the following parameters. Consumer will send fetch requests to each partition leader with a list of topics and a list of partitions from which it wants to read data. From the above example, consumer-1 will send fetch requests to both broker 1 (for t1-p0, t1-p1) and broker 3 (for t1-p4).
Consumer poll code looks like the following.
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9092");
props.setProperty("group.id", "conusmer-group-1");
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("topic-1", "topci-2"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
Controlling fetch size
There are four settings available to control amount of data returned by the broker per a fetch call
fetch.min.bytes fetch.max.wait.ms max.partition.fetch.bytes fetch.max.bytes
fetch-min-bytes ( defaults 1 byte)
Brokers will wait until a min bytes of data is available to return. The maximum amount of time can be set using fetch.max.wait.ms (higher value will improve throughput at the cost of latency)
fetch-max-wait-ms (defaults to 500ms)
Set an amount of time to wait if the fetch.min.bytes amount of data is not available.
max-partition-fetch-bytes (defaults to 1 MB)
Controls amount of data returned from each partition ( a single fetch can read from multiple topics and multiple partitions)
Fetch-max-bytes (defaults to 50MB)
Sets the maximum amount of data the broker will return per fetch request. This is per broker limit, so it is possible a single poll call might pull in more data than this into consumers as fetch requests will be sent to multiple brokers. Because of all these variables, it’s difficult to say how much memory will be used by the consumer, the following formula could be used to size the consumer (actually kafka consumer uses pipelining, so the maximum possible memory usage could be twice of this).
min(num brokers * max.fetch.bytes, max.partition.fetch.bytes * max_possible_partitions_per_consumer)
The max_possible_partitions_per_consumer defines the maximum number of partitions a consumer might be assigned. If the partitions are evenly distributed among the consumers, then it will be ceil(number_of_partions/number_of_consumers). One thing to note here is that if the consumers are started sequentially, it is possible for all partitions to be assigned to a single consumer then distributed to other consumers as they become available.
If the max.partition.fetch.bytes * max_possible_partitions_per_consumer is greater than the fetch.max.bytes, then we may end up starving partitions at the end of the fetch request. But this is handled by both kafka brokers and consumers. Kafka uses a round robin algorithm to provide a fair chance for each partition to be consumed by the consumer.
There is one more setting called max.poll.records, it doesn’t control the amount of data fetched from broker, but controls number records returned to user code.
Max-poll-records (defaults to 500)
max.poll.records controls number of records (not size) returned by a single poll call. This is the consumer side setting, this applied after data is fetched from the broker. If there are more records than this limit are fetched, they will be buffered until the user code consumes all of them.