Text To Avro DataFiles
Avro DataFiles are binary files that carry the schema with them. They are splittable and allows seeking to a random position. You can sync with record boundary . You need to define the schema of your data before you can write data to a DataFile(schema will have .avsc extension and data file will have .avro extension).
The following code will reads a simple CSV file and write it as Avro DataFile.
Schema of the Employee :
{ "name":"Employee",
"type":"record",
"doc":"employee records",
"fields":[{ "name":"empId", "type":"string" },
{ "name":"empName", "type":"string" }
]
}
CSV File format
empId,empName 10000,sankar 10001,anshu 10002,Rajesh 10003,Sravan
Writing Avro DataFiles
String srcUri=args[0];
String schemaUri=args[1];
String dstUri=args[2];
Configuration conf = new Configuration();
FileSystem fs=FileSystem.get(conf);
Schema.Parser parser = new Schema.Parser();
Schema schema=parser.parse(fs.open(new Path(schemaUri)));
InputStream is=fs.open(new Path(srcUri));
BufferedReader br=new BufferedReader(new InputStreamReader(is,"UTF-8"));
String line;
String[] csvSchema;
//Load CSV file column infromation, the schema should use same names
if(( line=br.readLine())!=null){
csvSchema=line.split(",");
}
else{
return;
}
GenericRecord datum=new GenericData.Record(schema);
DatumWriter<GenericRecord> writer =new GenericDatumWriter<GenericRecord>(schema);
DataFileWriter<GenericRecord> dataFileWriter =new DataFileWriter<GenericRecord>(writer);
dataFileWriter.create(schema, fs.create(new Path(dstUri)));
while(( line=br.readLine())!=null){
String[] values=line.split(",");
for(int i=0;i<values.length;i++){
datum.put(csvSchema[i],values[i]);
}
dataFileWriter.append(datum);
}
dataFileWriter.close();
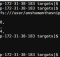
yarn jar HadoopAvro-1.0-SNAPSHOT.jar TextToAvro emp.csv emp.avsc emp.avro
First argument is the target CSV file, second argument is schema and third one is output file name. Full project is available oh github