Creating Hadoop maven project in eclipse
In this blog we will see how to create the wordcount example project in eclipse , we will be using maven as build tool.
File->New->Project -> Maven Project
Click next and select a workspace directory and click next,now you will be asked to select Archtype.
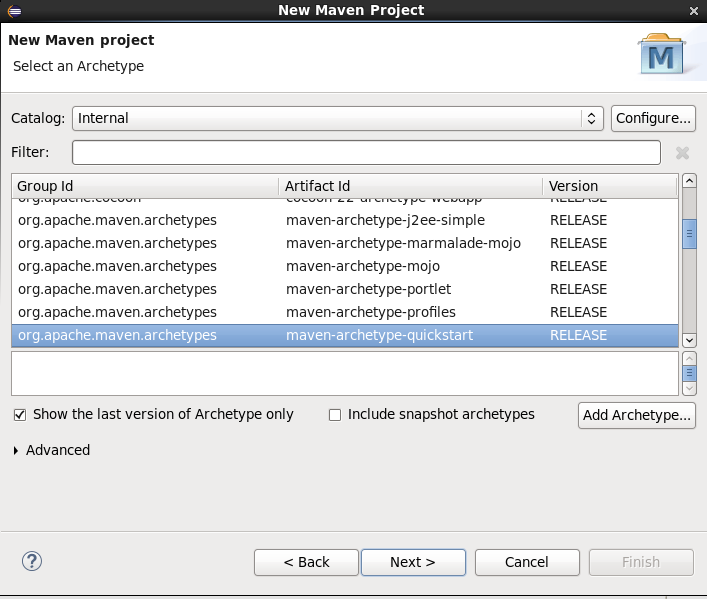
Select quickstart and click next.Provide your project name in Artifact Id
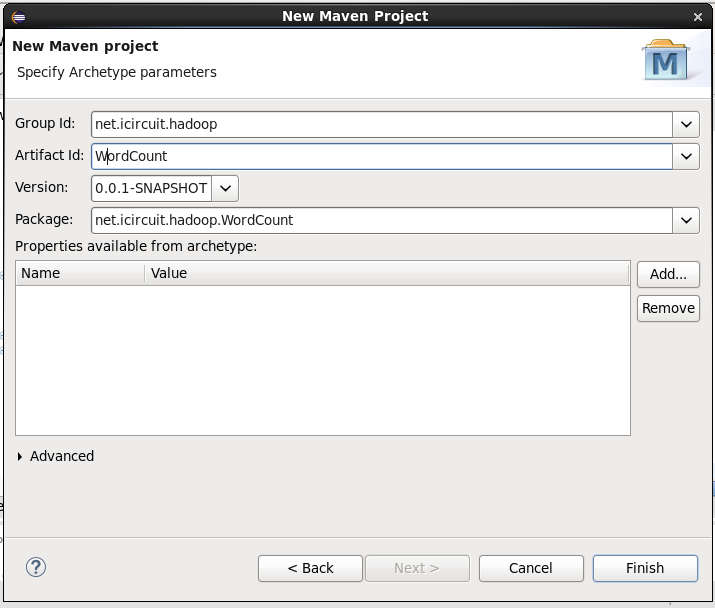
Click finish, if this is your first maven project, it will take some time to setup the project.
Now we need to add our dependencies to pom.xml, For word count we just need to add one dependency
The pom.xml looks like some thing like this
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>net.icircuit.hadoop</groupId>
<artifactId>wordcount</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>wordcount</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>2.6.0</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
Remove the App.java we don’t need it.
Create the following files and copy the code
WcDriver.java
package net.icircuit.hadoop.wordcount;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WcDriver extends Configured implements Tool{
public static void main(String[] args) throws Exception {
int exitCode=ToolRunner.run(new WcDriver(), args);
System.out.println("Exit code :"+exitCode);
System.exit(exitCode);
}
public int run(String[] arg0) throws Exception {
Job job=Job.getInstance();
job.setJobName("Word Count");
job.setJarByClass(WcDriver.class);
job.setMapperClass(WcMapper.class);
job.setReducerClass(WcReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(arg0[0]));
FileOutputFormat.setOutputPath(job, new Path(arg0[1]));
int ecode=job.waitForCompletion(true) ? 0:1;
return ecode;
}
}
WcMapper.java
package net.icircuit.hadoop.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Mapper;
public class WcMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
@Override
public void map(LongWritable key,Text value,Context context) throws
IOException,InterruptedException{
String line=value.toString();
String[] words=line.split(" ");
for(String word:words){
context.write(new Text(word),new IntWritable(1));
}
}
}
WcReducer.java
package net.icircuit.hadoop.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WcReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
@Override
public void reduce(Text key,Iterable<IntWritable> values,Context context) throws
IOException,InterruptedException{
int sum=0;
for(IntWritable value:values){
sum+=value.get();
}
context.write(key, new IntWritable(sum));
}
}
Open terminal and navigate to the root of the project, then build the project
mvn clean install
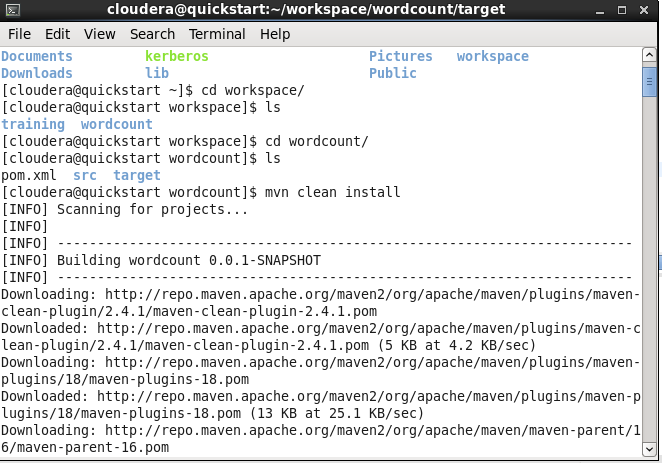
The jar well be available in the target folder.
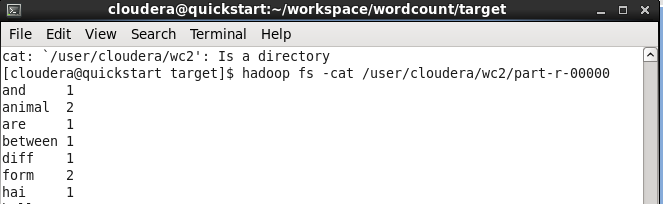
yarn jar wordcount-0.0.1-SNAPSHOT.jar net/icircuit/hadoop/wordcount/WcDriver {Input path} {Output path}
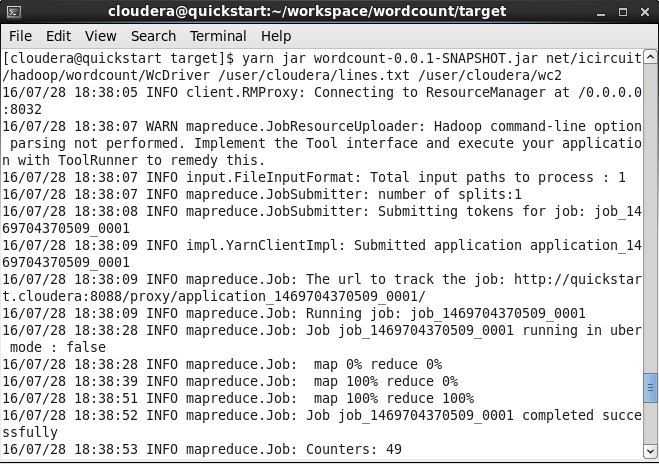
Output of the reducer