Running Map Reduce Job on Avro Data Files
In the previous blog we have seen how to convert a text file to Avro data file.In this blog we will see how to run a map reduce job on Avro data file. We will use the output generated by the TextToAvro job.
The job will count number of films released in each year. The map function will extract year of the film for each record and send it to reducer as a AvroKey .
Input file schema :
Though it has all the fields present in the input data, we will be using only the year
{
"name":"movies",
"type":"record",
"fields":[
{"name":"movieName",
"type":"string"
},
{"name":"year",
"type":"string"
},
{"name":"tags",
"type":{"type":"array","items":"string"}
}
]
}
We will be using TextOutputFormat to write the output.
Program
public class CountMoviesByYear extends Configured implements Tool{
public static void main(String[] args) throws Exception {
int exitCode=ToolRunner.run(new CountMoviesByYear(), args);
System.out.println("Exit code "+exitCode);
}
public int run(String[] args) throws Exception {
Job job=Job.getInstance(getConf(),"CountMoviesByYear");
job.setJarByClass(getClass());
job.setMapperClass(MovieCounterMapper.class);
job.setReducerClass(MovieCounterReducer.class);
Schema.Parser parser = new Schema.Parser();
Schema schema=parser.parse(getClass().getResourceAsStream("movies.avsc"));
AvroJob.setInputKeySchema(job, schema);
AvroJob.setMapOutputKeySchema(job, Schema.create(Schema.Type.STRING));
AvroJob.setMapOutputValueSchema(job, Schema.create(Schema.Type.INT));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(AvroKeyInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0:1;
}
public static class MovieCounterMapper extends Mapper<AvroKey<GenericRecord>,NullWritable,AvroKey<String> ,AvroValue<Integer> >{
public void map(AvroKey<GenericRecord> key,NullWritable value,Context context) throws IOException,InterruptedException{
context.write(new AvroKey(key.datum().get("year")), new AvroValue(new Integer(1)));
}
}
public static class MovieCounterReducer extends Reducer<AvroKey<String> ,AvroValue<Integer>,Text,IntWritable>{
@Override
public void reduce (AvroKey<String> key,Iterable<AvroValue<Integer> > values,Context context) throws IOException,InterruptedException{
int count=0;
for(AvroValue<Integer> value:values){
count+=value.datum().intValue();
}
context.write(new Text(key.datum().toString()), new IntWritable(count));
}
}
}
Running the Job
export HADOOP_CLASSPATH=/path/to/avro-mapred-1.7.4-hadoop2.jar yarn jar HadoopAvro-1.0-SNAPSHOT.jar CountMoviesByYear -libjars avro-mapred-1.7.4-hadoop2.jar movies/part-r-00000.avro moviecount1
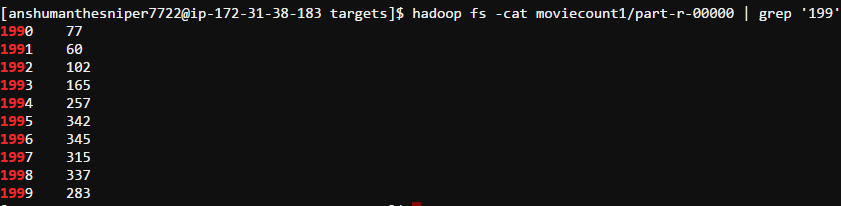
Output of the job