Seeing is Believing – Dlib way
Human eyes are very powerful.
- They see,
- They look,
- They observe,
- They analyze,
- They interpret,
- They describe…
Human eye is of 576 megapixel (Mobile cameras are just having 18 MP) They can process 36K bit information every hour.
Face recognition and object recognition are the main functions of human eye.
All most of all the tasks we do on daily basis require these two important functions – Face and object recognition.
Capture, analyze for pattern matching are the steps involved.
Technology is always looking to help human efforts and make it convenient for human tasks. Communication world has grown beyond imagination. Machine learning , deep learning evolved now so as to make these tasks possible for the machines.
There are many methods/algorithms for this.
In this blog, I shall explain the steps involved for creating face detection and object detection using DLib & openCV.An example of the detector’s output on a new image (i.e. one it wasn’t trained on) is shown below: (red boxes around faces)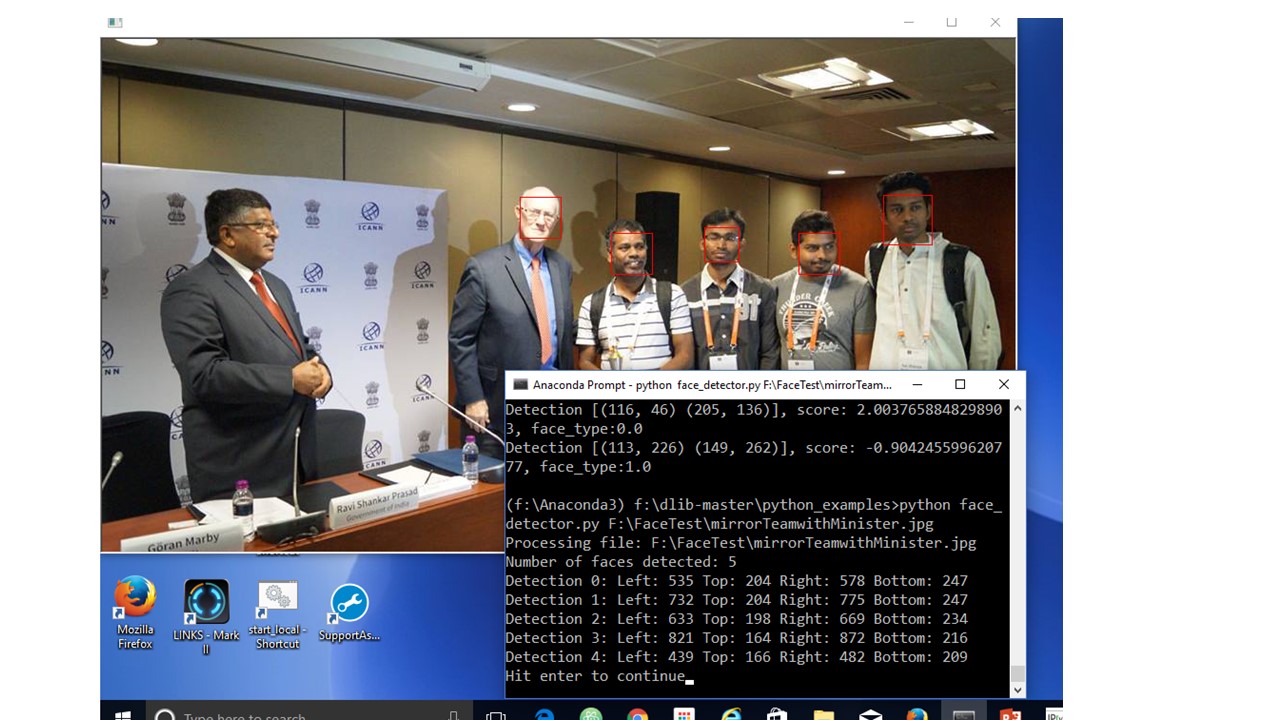
What is Dlib
Dlib is a general purpose cross-platform software library written in the programming language C++. Its design is heavily influenced by ideas from design by contract and component-based software engineering. Thus it is, first and foremost, a set of independent software components. It is open-source software released under a Boost Software License. much of the development has been focused on creating a broad set of statistical machine learning tools and in 2009 dlib was published in the machine learning journal
What is openCV
OpenCV (Open Source Computer Vision) is a library of programming functions mainly aimed at real-time computer vision. Originally developed by Intel, it was later supported by Willow Garage and is now maintained by Itseez.The library is cross-platform and free for use under the open-source BSD license.
Setting up the system:
for windows 10 OS and Python , Algorithm used : HOG and SVM
1. Install Anaconda so that compiling the C++ library and other dependencies can be resolved. Dowload link https://www.continuum.io/downloads
Verification
(f:\Anaconda3) F:\dlib-master\python_examples>python --version Python 3.6.1 :: Anaconda custom (64-bit)
Detailed install instructions: https://docs.continuum.io/anaconda/install/windows
2. Install Dlib
conda install -c conda-forge dlib
3. Install openCV3
conda install -c conda-forge opencv
(note: conda-forge is not mandatory , I used this custom method)
4. Clone Davis King Dlib Git
https://github.com/davisking/dlib/
5. Train faces and run the test image
$ cd ~/dlib/python_example $ python train_object_detector.py ../examples/faces/ $ python ~/object_detect_with_dlib.py
After training, we can get the SVM of the face – 2 eyes, nose and mouth are the key features
6. I ran the award ceremony image , All team members faces were detected. For some reasons, Minister’s face is not recognized.
7. After detecting , we can compare and make recognition with known faces.
Next part of the exercise is to identify the objects.
Since we need to create imglab executable, additional installations are required
Cmake : https://cmake.org/files/v3.9/cmake-3.9.1-win64-x64…
Visual studio 2015 : if it is not there
Build imaglab.exe using this command
cd ~/dlib/tools/imglab/ && mkdir build && cd build && cmake .. && cmake --build . --config Release
Now we need to train the system to understand what object we are going to identify.
Task : I want to identify pedestrian symbol/signal including different type/size. I used 5 google images for training.
Training images
(f:\Anaconda3) F:\dlib-master\python_examples>imglab -c training.xml F:\PCimages\pc_1.jpg F:\PCimages\Pc_2.jpg F:\PCimages\pc_3.jpg f:\PCimages\pc_4.jpg f:\PCimages\PC_5.jpg
After that run the imglab.exe, to mark the region and label it. (Holding down shift and mark the rectangle to mark the required area). After training all images, save it and exit
(f:\Anaconda3) F:\dlib-master\python_examples>imglab.exe training.xml
Then run the detector with the test image
(f:\Anaconda3) F:\dlib-master\python_examples>python train_object_detector.py F:/dlib-master/tools/imglab/build/Release/
Given below is the outcome of the new pedestrian symbol identified
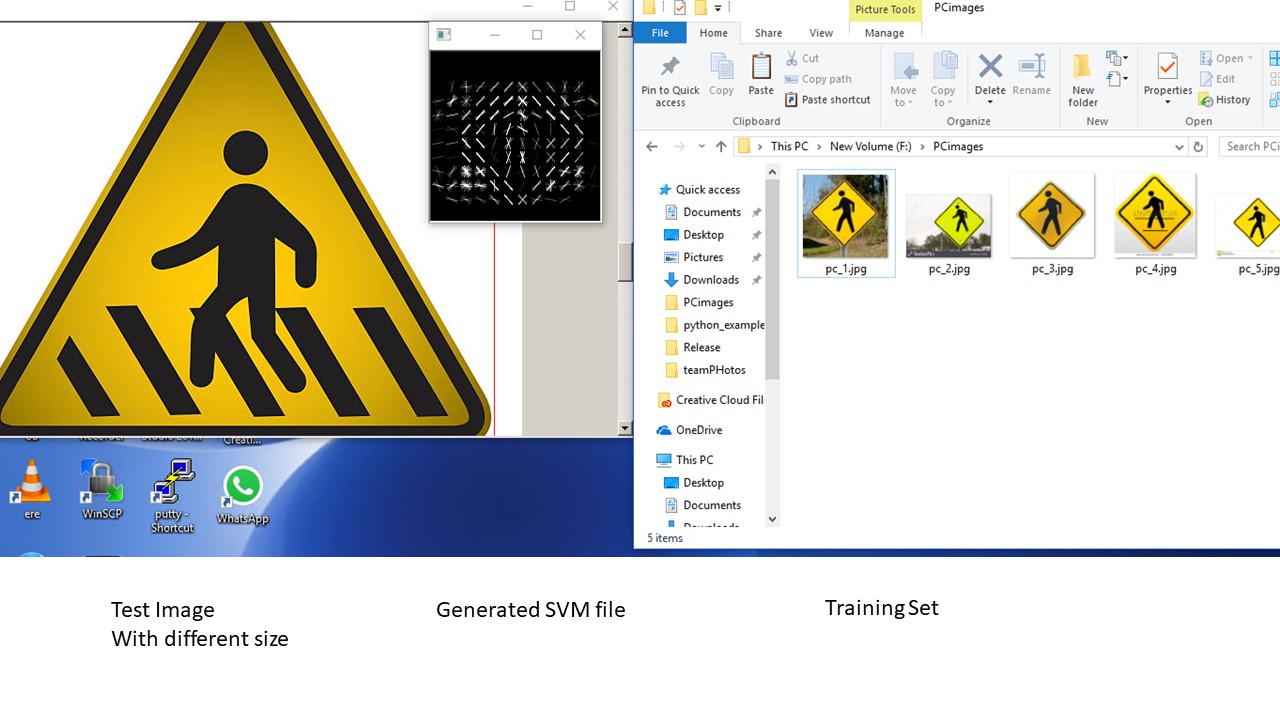
For the disabled persons, this utility can be useful, we can make this identification speak whenever pedestrian symbol is available.
Identifying the image can do real wonders in real life. For example, one of my friend built a solution using this technique to identify the out of stock in the shelf in store shelves, by counting the faces of the bottles, packets.
References
https://gist.github.com/atotto/c1ccbfa44ee70a47681…
https://gist.github.com/iandees/f773749c47d0887051…
http://blog.dlib.net/2014/02/lib-186-released-make…
What usecase you can think to help the society? Comment your views.
Related Posts


About The Author
Sivaiots
Enterprise Architect , Tinkerer