Hadoop Block caching
When ever a request is made to a data node to read a block, the data node will read the block from disk. If you know that you will read the block many times, it is good idea to cache the block in memory. hadoop allows you to cache a block. You can specify which file to cache (or directory) and for how long (The block will be cached in off-heap caches).
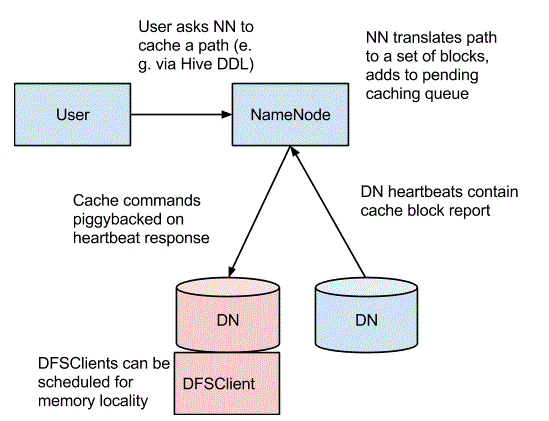
Hadoop provides centralized cache management to manage the block caches. All the cache requests are made to namenode, namenode will instruct the respective datanodes to caches the blocks in off-heap caches. Hadoop uses native libraries to cache the blocks, so you should enable JNI. A cache directive specifies which file/directory to be cached and their properties like Time to live.
cache pool is the administrative entity used to manage groups of cache directives. You can enforce permissions and limits on pool level.
cacheadmin
cacheadmin allows you to interact with cache pools and cache directives from command line
hdfs cacheadmin

You can read more about block cache here.