Redis Bloom Filters : Design for large scale uniqueness verification
Many applications has the requirement of making sure that certain user provided fields are unique in the system. For example a web application has to make sure that the usernames are unique for each registered user. In this post will see how to design a system that can do this at scale using Redis bloom filters.
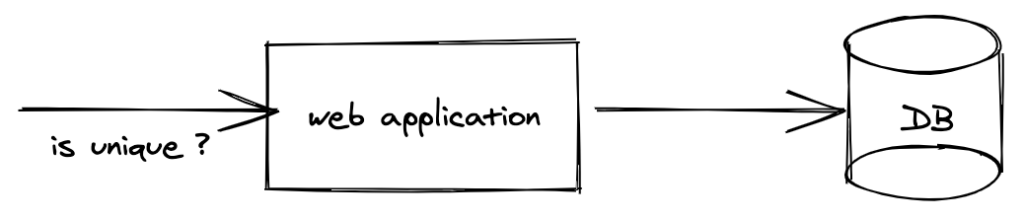
Applications allow users to pick their username at the time registration. On small scale systems, we can query the data base and tell if the username is already used or not (You also need to make sure to have unique constraint on field at database level). This design might be difficult scale as the registration rpm increases.
Introducing Cache
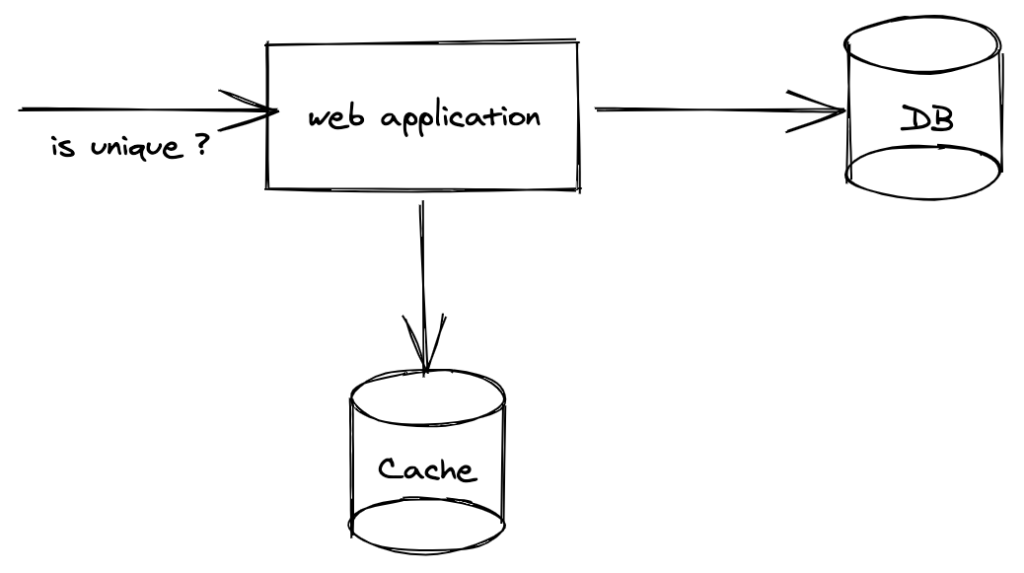
We can introduce a redis cache to speed up the queries. We can use a redis set and add all the username to the set. When a request comes to verify the username we only need see the cache, no need to hit the database. We also need to update the cache whenever a new username is added to the database.
This works well if we can afford plenty of memory required to keep every username in memory. For example if each records takes 20 bytes of memory, we need 20GB of memory for storing 1 billion records.
Uniqueness test with bloom filters
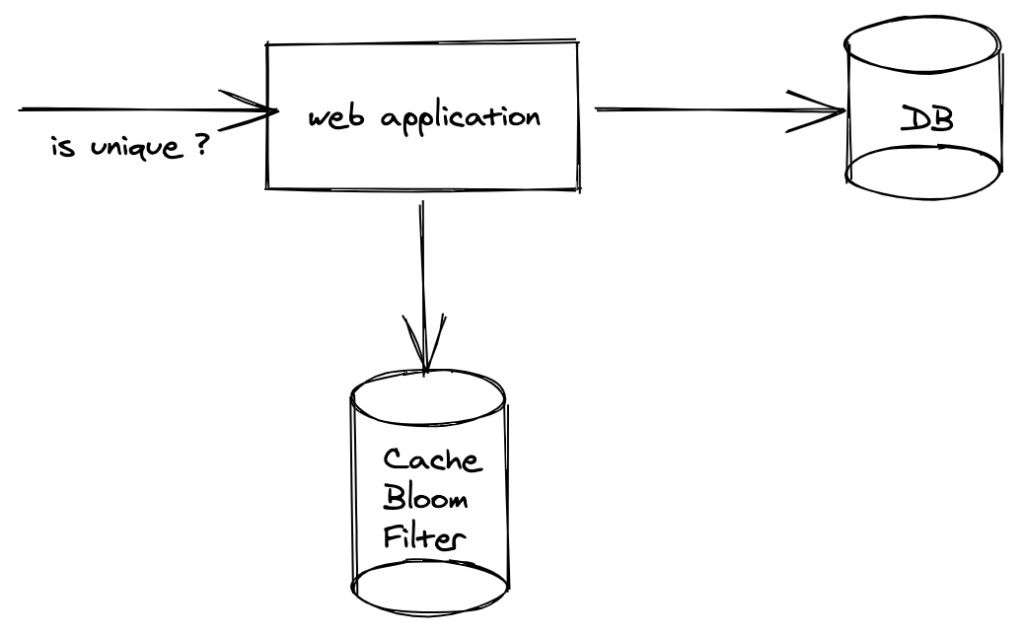
If you are concerned about memory requirements of above method, you can considered using bloom filters. Bloom filters are probabilistic data structures. There is a possibility of false positives but never false negatives. if filter says that item is not present in the set we can be sure that the item was never stored in filter where as if the filter reports it had seen an item, it might or might not have seen that item. This error rate can be controlled.
Bloom filters don’t store full item, so it doesn’t need 20 bytes to store the item. The memory requirement is a function of required error rate (false positive).
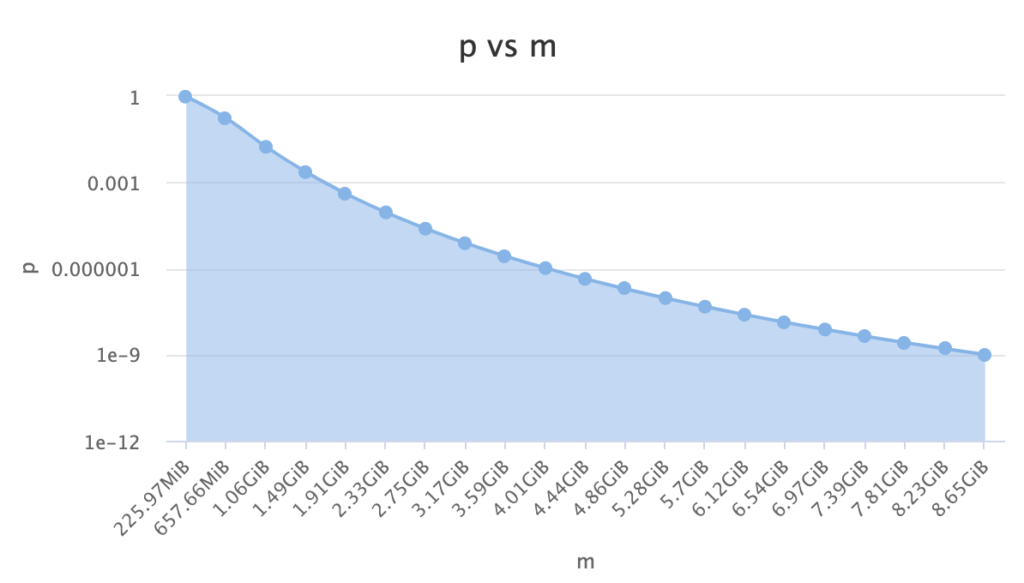
To store 1 billion records with 0.001 false positive probability we only need 1.67 GB.
Redis bloom filters with Java
First we need to install a version of redis that’s built with BloomFilter module. You can download a pre-compiled version or use following docker image
docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest
popular redis SDK for Java Jedis doesn’t have support for redis bloom filter module. We need to add JReBloom dependency to our project.
<dependencies>
<dependency>
<groupId>com.redislabs</groupId>
<artifactId>jrebloom</artifactId>
<version>2.0.0</version>
</dependency>
</dependencies>
implementation group: 'com.redislabs', name: 'jrebloom', version: '2.0.0'
The library provides a Client class which provides all the necessary methods to interact with the bloom filter. The Client constructor accepts a JedisPool or redis server details.
@Bean
public JedisPool jedisPool(){
JedisPoolConfig config = new JedisPoolConfig();
poolConfig.setMinIdle(minIdle);
poolConfig.setMaxIdle(maxIdle);
poolConfig.setMaxTotal(maxTotal);
return new JedisPool(config,hostName,
port,connectTimeout,password);
}
Client client = new Client(jedisPool);
Once the client object is available we can add items or check if an item exists in the filter using add or exists methods.
client.add(BF_KEY,"username-1");
client.exists(BF_KEY,"username-1");